재량 지출 – 중앙 경향 이해하기
재량 지출이란 무엇인가요?
재량 지출은 비필수 구매로, 욕구에 해당하며, 즐거움, 편리함 또는 재미를 위해 구매하는 것입니다. 예를 들어, 오락, 외식 또는 최신 기술 기기가 있습니다. 반면에 필요는 생존에 필수적인 것들로, 음식, 주거, 공공요금 및 의료 서비스가 포함됩니다. 필요와 욕구의 차이를 아는 것은 중요한 재정 기술로, 특히 자신의 돈을 관리하기 시작할 때 중요합니다.

왜 중요한가요
필요와 욕구의 차이를 이해하면 더 스마트한 재정 선택을 할 수 있습니다. 예를 들어, 새 비디오 게임을 위해 저축했지만 전화기가 고장났다면, 무엇을 선택하시겠습니까? 전화기는 필요이고, 게임은 욕구입니다. 전화기를 교체하기로 선택하면 필수 지출을 충족하게 되어 장기적으로 재정적 안전을 확보할 수 있습니다.
필요 vs. 욕구 분석: 데이터 접근법
지출을 추적하면 재정 습관의 패턴을 드러낼 수 있습니다. 친구들과 함께 비필수 항목인 간식, 오락 또는 앱에 얼마나 지출하는지 추적할 수 있습니다. 이 데이터를 검토함으로써 지출이 자신의 우선순위와 일치하는지 반성할 수 있습니다.
실제로 연구에 따르면 장기적으로 생각하는 사람들은 더 많이 저축하는 경향이 있으며, 즉각적인 만족에 집중하는 사람들은 과소비할 가능성이 더 높습니다. 지출 데이터를 분석하면 더 나은 재정 결정을 내리고 건강한 돈 습관을 기르는 데 도움이 될 수 있습니다.
지출 데이터 분석을 위한 중앙 경향 사용하기
지출을 분석할 때, 세 가지 주요 중앙 경향 측정값인 평균, 중앙값, 최빈값이 재정 행동을 요약하는 데 도움이 됩니다:
- 평균: 모든 지출의 평균입니다. 유용하지만, 평균은 극단적인 값(다른 사람들보다 훨씬 많이 또는 적게 지출하는 경우)에 의해 왜곡될 수 있습니다.
- 중앙값: 모든 데이터가 정렬되었을 때의 중간 값입니다. 이는 이상치를 피하여 전형적인 지출에 대한 더 나은 아이디어를 제공합니다.
- 최빈값: 가장 빈번한 값입니다. 이는 지출에서 일반적인 습관이나 인기 있는 트렌드를 식별하는 데 도움이 될 수 있습니다.
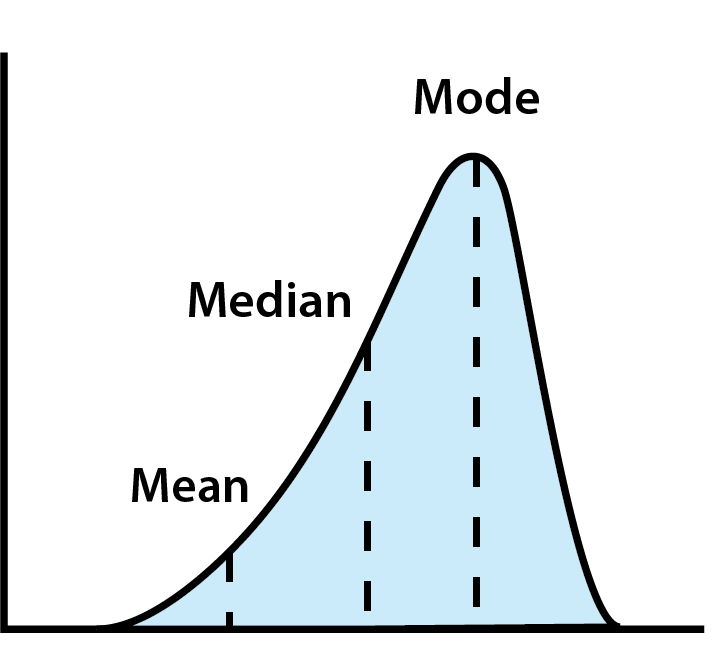
지출 데이터 분석을 위한 중앙 경향 사용하기
중앙 경향을 살펴보면 자신의 예산을 더 잘 이해할 수 있습니다. 예를 들어, 매일 아침 학교나 직장에 가는 길에 커피를 사는 경우가 있습니다. 이로 인해 지출이 누적될 수 있다는 것을 깨닫지만, 자신이 다른 사람과 비슷한 정도로 지출하고 있다고 생각하므로 합리적인 지출이라고 생각합니다.
하지만 실제로 동료들에게 얼마나 지출하는지 물어보면, 매달 실제로 얼마나 지출하고 있는지에 대한 더 큰 관점을 얻을 수 있습니다.
- 평균: 평균과 비슷한 정도로 지출하고 있다면, 자신의 지출 습관에 대해 맞았던 것입니다. 하지만 다른 사람들보다 훨씬 더 많이 지출하고 있다면, 음료 선택을 좀 더 면밀히 살펴볼 수 있습니다.
- 중앙값: 중앙값은 당신의 행동이 다른 사람들과 어떻게 맞물리는지를 알려줍니다. 여러 사람이 커피에 $0를 지출한다면, 이는 평균을 전형적인 커피 소비자가 지출하는 것보다 낮게 왜곡할 수 있습니다. 이 경우, 당신이 실제로 중앙값보다 적게 지출하고 있다면, 당신의 지출은 합리적이라고 볼 수 있습니다.
- 최빈값: 가장 빈번한 값입니다. 아마도 친구들이 매일 아침 같은 오렌지 모카 프라푸치노를 주문하고 있다면, 이는 최빈값이 됩니다. 오렌지 모카 프라푸치노가 비싸다는 것을 알고 있다면, 이는 중앙값이 당신이 생각하는 전형적인 커피 소비자가 주문하는 것보다 높게 왜곡될 수 있음을 의미할 수 있습니다.
예시: 에스테반의 커피 습관
에스테반은 매일 아침 $4.75의 커피를 구매합니다. 그는 이것이 합리적인 가격이라고 믿지만, 일반적인지 궁금해합니다. 평균 비용을 더 잘 이해하기 위해, 그는 친구, 가족 및 동료들에게 아침 커피에 얼마나 지출했는지 물어봅니다. 그들의 응답은 다음과 같습니다:

| 응답자 | 오늘 아침 얼마나 지출했는가 |
|---|---|
| 1 | $0.00 |
| 2 | $6.95 |
| 3 | $1.99 |
| 4 | $0.00 |
| 5 | $4.25 |
| 6 | $3.00 |
| 7 | $5.99 |
| 8 | $7.37 |
| 9 | $0.00 |
| 10 | $8.19 |
| 11 | $7.59 |
| 12 | $0.00 |
| 13 | $24.68 |
| 14 | $0.00 |
| 15 | $8.09 |
1. 평균 계산하기
먼저, 에스테반은 자신의 첫 번째 가설을 테스트하고 싶어합니다 – 그는 다른 모든 사람들과 비슷한 평균을 지출하고 있다고 생각합니다. 그래서 그는 평균, 즉 산술 평균을 계산할 것입니다. 평균을 계산하는 공식은 다음과 같습니다:
평균 = 관찰의 합 / 관찰 수
공식은 시그마 표기법으로도 작성할 수 있습니다:
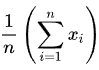
시그마 표기법에서 시그마 기호(Σ)는 “합산하다”를 의미하고, n 기호는 관찰 수를 의미하며, x는 특정 관찰에 대한 것을 의미하고, i는 각 관찰에 대한 것을 의미합니다. 따라서 이것은 첫 번째(i = 1, 시그마의 하단)부터 마지막 관찰(n, 시그마의 상단)까지 모든 값을 합산한 다음 1/n을 곱하라는 의미입니다. 시그마 표기법은 연구 분야에서 매우 일반적이며, 이는 일련의 숫자에 대해 대수 또는 수학적 연산이 적용되는 것을 보여줍니다.
따라서 우리는 모든 관찰을 합산합니다:
$0.00 + $6.95 + $1.99 + $0.00 + $4.25 + $3.00 + $5.99 + $7.37 + $0.00 + $8.19 + $7.59 + $0.00 + $24.68 + $0.00 + $8.09 = $78.10
그리고 15로 나눕니다 (관찰 수)
$78.10 / 15 = $5.21
에스테반은 맞았습니다 – 그는 평균보다 적게 지출하고 있습니다. 그의 $4.75는 평균 값인 $5.21보다 저렴합니다.
2. 중앙값 계산하기
중앙값을 계산하기 위해서는 가장 작은 값부터 가장 큰 값까지 순서를 재배열해야 합니다. 중앙값은 중간 숫자입니다.
| 응답자 | 오늘 아침 지출한 금액 |
|---|---|
| 1 | $0.00 |
| 4 | $0.00 |
| 9 | $0.00 |
| 12 | $0.00 |
| 14 | $0.00 |
| 3 | $1.99 |
| 6 | $3.00 |
| 5 | $4.25 |
| 7 | $5.99 |
| 2 | $6.95 |
| 8 | $7.37 |
| 11 | $7.59 |
| 15 | $8.09 |
| 10 | $8.19 |
| 13 | $24.68 |
그의 친구들, 가족, 동료들의 아침 커피 지출의 중간값(중앙값)은 실제로 $3.00으로, 에스테반의 $4.75보다 상당히 낮습니다. 이 발견은 에스테반이 자신의 일상적인 커피 습관에 대해 덜 편안하게 느끼게 만듭니다. 그는 자신의 개별 비용이 평균 가격보다 낮음에도 불구하고 동료들보다 50% 더 지출하고 있다는 것을 깨닫습니다.
3. 최빈값 계산하기
마지막으로, 에스테반은 가장 인기 있는 선택이 무엇인지 알고 싶어합니다. 이를 위해 그는 최빈값을 찾아야 합니다. 최빈값은 단순히 가장 일반적인 관찰입니다. 그의 설문 조사에서 5명이 $0.00을 응답했으며 – 이는 가장 일반적인 선택(최빈값)입니다. 비록 대다수의 사람들은 아니지만, 이는 평균 및 중앙값 선택에 큰 영향을 미칩니다. 에스테반은 이 정보를 가지고 무엇을 해야 할지 잘 모르겠지만, 답을 찾기 위해 더 많은 수학이 필요합니다!
데이터 해석: 왜곡, 이상치 및 분포
에스테반은 자신의 분석에서 응답의 분포에서 오는 문제를 살펴보고 있습니다 – 즉, 그의 응답이 그래프에서 어떻게 보이는지에 대한 것입니다.
왜곡
정규 분포는 깔끔한 종 모양을 가지고 있습니다. 완벽한 정규 분포는 평균, 중앙값, 최빈값이 모두 동일하게 됩니다.
모두 동일하지 않다면, 데이터가 왜곡되어 있다는 것을 의미합니다 – 이 경우, 그의 데이터는 오른쪽으로 왜곡된 분포를 가지고 있다고 말하며, 이는 중앙값이 평균보다 낮다는 것을 의미합니다. 이는 종종 정말 큰 숫자나 정말 작은 숫자가 몇 개 있을 때 발생하여 차트가 오른쪽으로 긴 경사를 가진 것처럼 보이게 만듭니다.
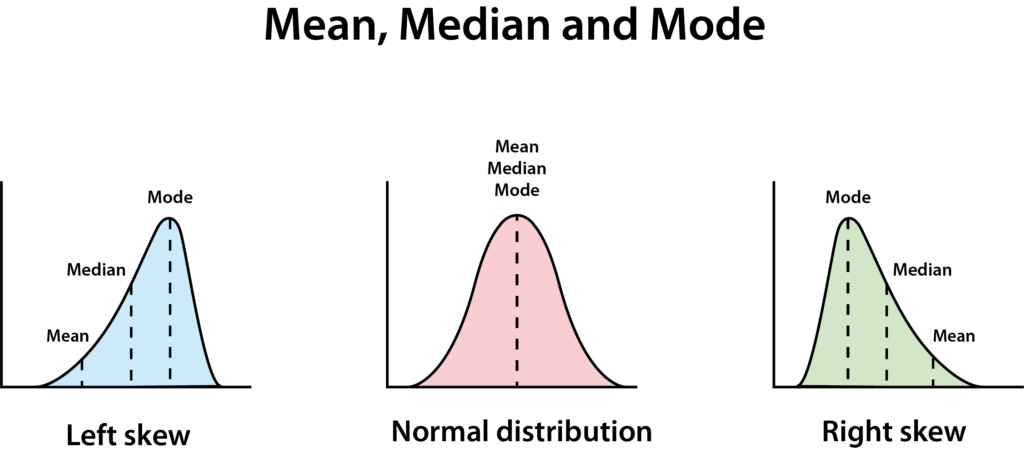
이상치
에스테반이 응답을 자세히 살펴보면, 하나의 이상치를 발견합니다: $24.68의 비용입니다. 이 값은 다른 어떤 것보다도 상당히 높습니다. 이상치는 나머지 그룹에서 멀리 떨어진 데이터 포인트로, 결과를 왜곡할 수 있기 때문에 종종 통계 분석에서 제외됩니다.
더 조사해보니, 에스테반은 이 이상치가 그 사람의 가족 전체를 위해 그날 아침에 구입한 갤런의 신선한 오렌지 주스의 비용을 나타낸다는 것을 알게 됩니다. 이 비용은 일반적인 커피 한 잔의 비용과는 분명히 비교할 수 없습니다.
이중봉 분포
이중봉 분포는 빈도 분포를 살펴볼 때 하나의 봉우리가 아니라 두 개(또는 그 이상)의 봉우리가 보일 때 발생합니다. 고등학생들이 특정 날 점심에 얼마를 지불했는지에 대한 이 설문 응답을 살펴보세요:
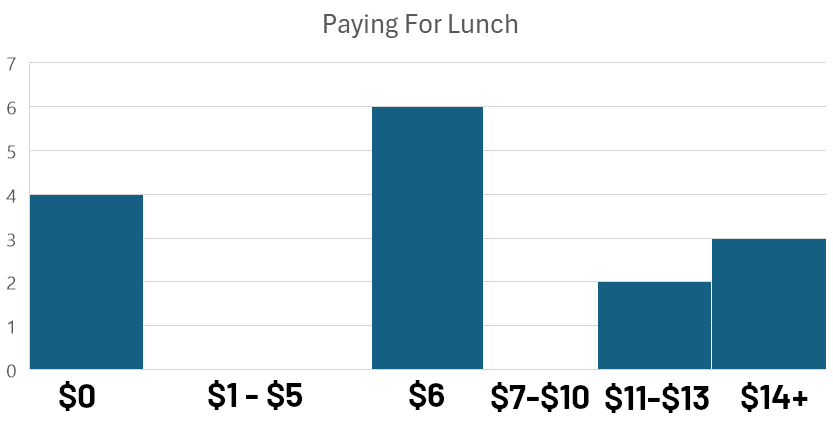
데이터가 시각적 비교를 위해 구간 또는 ‘빈’으로 그룹화된 이 유형의 차트를 히스토그램이라고 합니다. 이러한 빈 내에서 관찰이 어떻게 분포되어 있는지를 분석하는 것을 빈도 분석이라고 합니다.
히스토그램을 관찰하면 두 개의 뚜렷한 봉우리가 보입니다: 하나는 $0 근처에, 다른 하나는 $6 근처에 있습니다. 이 이중봉 분포(모드가 $0과 $6 근처에 있는)는 데이터 내에 두 개의 뚜렷한 그룹이 있음을 시사합니다.
이 봉우리를 식별하는 것은 다음과 같은 질문을 유도하여 추가 연구를 안내할 수 있습니다:
- 이 두 가지 뚜렷한 지출 패턴을 설명할 수 있는 요인은 무엇인가요?
- 이 봉우리가 이 그룹의 개인들의 기본 동기와 행동에 대해 무엇을 드러내고 있나요?
더욱이, 이 두 봉우리가 존재한다는 것은 오른쪽으로 왜곡된 분포를 나타내며, 이는 데이터 포인트의 더 큰 비율이 가격 범위의 하단에 집중되어 있음을 의미합니다.
이중봉 데이터는 반드시 동일한 수의 관찰이 있는 두 개의 응답이 있다는 것을 의미하지는 않으며, 단지 두 개의 뚜렷한 봉우리가 보인다는 것을 의미합니다(이 경우 $6가 “진정한 모드”입니다).
연구자들이 데이터를 더 자세히 살펴보았을 때, 설명은 명확해졌습니다. $0은 집에서 도시락을 가져온 학생들이고, $6은 일반 학교 점심의 비용이었습니다. $10 이상을 지불한 학생들은 학교의 스낵 바에서 아이템을 조합하여 구매하거나 학교 가는 길에 구입한 다른 음식을 사는 것이었습니다.

결론: 데이터를 사용하여 더 나은 재정 결정을 내리기
이 세 가지 중심 경향 측정치인 평균, 중앙값, 최빈값을 이해함으로써, 데이터를 해석하고 더 나은 재정 선택을 할 수 있습니다. 지출을 분석하든 더 큰 추세를 살펴보든, 이러한 도구는 더 나은 돈 습관을 개발할 수 있도록 도와줍니다. 지출 데이터를 수집하고 분석하는 것은 재정 행동에 대한 통찰력을 제공할 수 있습니다.
에스테반과 같은 학생들에게는, 단순한 변화—예를 들어, 재량 지출을 줄이는 것—가 장기적인 재정적 이익으로 이어질 수 있습니다. 에스테반이 자신의 지출이 중앙값보다 높고, 가장 인기 있는 선택이 전혀 지출하지 않는 것임을 알게 되면, 그의 지출 결정과 그것이 그의 미래에 의미하는 바에 대한 맥락을 제공하는 데 도움이 됩니다.